A while back I came acros an excellent article by Artem Krylysov called Let’s build a Full-Text Search engine . The article explains the core concept behind constructing an inverted index - an index mapping string tokens to the documents containing them (see Inverted Index). This indexing technique enables very fast searches across a large corpus of documents - a technique for full-text search. I highly recommend starting by reading that article.
The original article describes a GOLANG implementation. I wanted to try building the full application described in the article, using Java. This turned out to a be a very illuminating and fun exercise! The Java implementation here follows the implementation ideas laid out in the original very closely. However, I did try out some new ideas that were suggested in the article, viz.,
- Efficient Data Storage: Using Roaring Bitmap for a compact and optimized representation of document IDs.
- Persistence with RocksDB: Storing the inverted index and document database on disk, allowing data to be loaded into memory at startup.
The rest of this post is a description of the key implementation elements. The process is outlined in the diagram below:
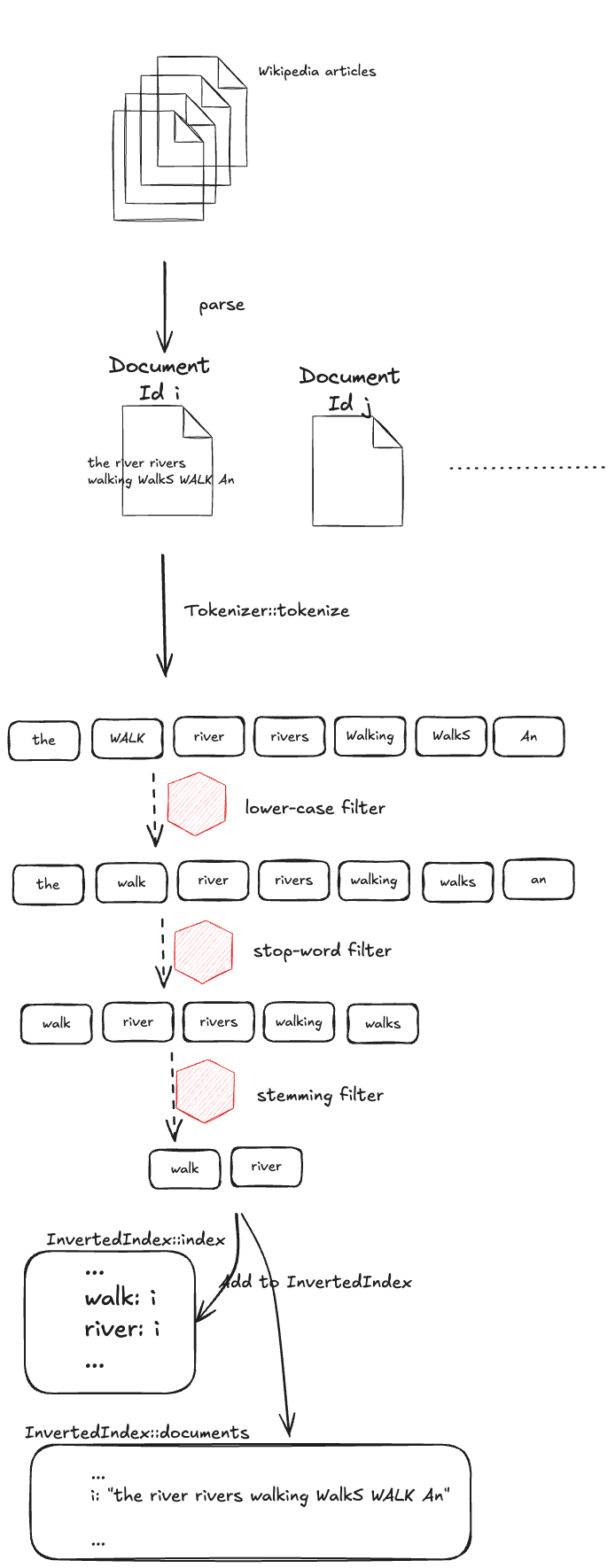
- Parse the XML documents (Wikipedia articles) and assign a unique identifier to each document.
- Tokenize the document.
- Apply Filters to process and refine tokens.
- Store Token-Document Mapping in the inverted index.
- Store Document Content in a document database.
Parsing an XML document Link to heading
The XML document parser -
WikipediaDocumentParser::parse is a XML parser to parse a Wikipedia corpus. This implementation parses the corpus enwiki-latest-abstract.xml.gz. The parsed content is returned as a vector of Document types. Each Document holds the following key pieces of information -
- The document identifier - computed locally by the application
- The document content - this is a abstract of a real Wikipedia article itself. This content is later broken down into tokens by an
Analyzer
Building the Inverted Index Link to heading
Once we have a vector of Document types, we now need to use this to build our inverted index. The class InvertedIndex holds the underlying inverted-index data stores, and some routines to enable the bootstrapping of the index. The class is composed of two key data structures holding the data stores.
The actual inverted index -
public final ConcurrentHashMap<String, Roaring64Bitmap> index;indexis the key data structure and it maps a string token - an “analyzed” token from a Document - to a list of document identifiers that contain the token.A database of documents extracted from the input XML
public final HashMap<Long, Document> documents;documentsis the other key data structure. It maps a document id to the actual document content.
Adding a document to the inverted index Link to heading
The InvertedIndex class addToIndex method is responsible for adding all the parsed Document objects to the inverted index.
public void addToIndex(final Document document) {
final int docIdInt = (int)document.id();
final String[] docTokens = Analyzer.analyze(document.abstractText());
Arrays.stream(docTokens).forEach(token ->
index.computeIfAbsent(token, k -> new Roaring64Bitmap()).add(docIdInt)
);
documents.put(document.id(), document);
}
As the original article describes it, the Wikepedia article contents, stored in Document objects, are turned into tokens by the Analyzer. The Analyzer is composed of multiple filters -
Lowercase filter- to convert all tokens into lower caseStopword filter- removes common words from the token listStemming filter- It reduces all words to their base form. I found this to a really interesting concept.
public static String[] analyze(final String entry) {
String[] tokens = Tokenizer.tokenize(entry);
final var lowerCaseFiltered = lowerCaseFilter.filter(tokens);
final var stopWordFiltered= stopWordFilter.filter(lowerCaseFiltered);
final var stemmed = stemmerFilter.filter(stopWordFiltered);
return stemmed;
}
The document content is broken down into tokes, and the tokens are fed through a chain of filters. A series of these filters generate a final list of token to store in the index. The tokens generated from a document are associated with a document id. The inverted index is then updated with the token ⇒ document id information. The secondary documents database is also updated so that given a document id, we can retrieve the original document contents from it.
Optimized document id storing Link to heading
My implementation uses the Java Roaring Bitmap library. This leads to tremendous savings to both on-disk, and in-memory space requirement. The contrast to this would be using a Set of Long values, which would be much more expensive from a storage perspective. An added advatage to using Roaring64Bitmap data type is that it has built-in intersection function. That helps us with the search operation - where we have to find out the intersection of multiple logical set of document ids that contain our search terms.
Persistence Link to heading
This implementation has the capability to persist the inverted index, and the document database, to disk in a RocksDB database. This functionality is in the InvertedIndexPersistence class. The application reads back entire index and document database from the RocksDB database at startup. This gives us the ability to not have to recompute the index each time the application starts up. It does load in the entire index into memory though.
Searching the index Link to heading
The incoming query string is broken down into tokens, again using the same Analyzer that the index construction process uses. The application then consults the inverted index to search for documents that contain all the query terms. This implementation (reproduced below), makes use of the Roaring Bitmap and and or methods to do an effective logical and operation - we want to find all documents that contain all the search terms
public Roaring64Bitmap searchIndex(final String searchString) {
final String[] searchTokens = Analyzer.analyze(searchString);
Roaring64Bitmap result = null;
for (String str : searchTokens) {
Roaring64Bitmap bitmap = index.get(str);
if (bitmap != null) {
if (result == null) {
result = new Roaring64Bitmap();
result.or(bitmap);
} else {
result.and(bitmap);
}
}
}
return result;
}
The search process is two steps -
- Find all document ids for all the tokens in the search string
- Retrieves all documents based on the document ids
Frontend Link to heading
My implementation also provides a frontend as an interface to accept search queries. It uses the lightweigth Javalin web framework to expose the /search?text=<search terms> endpoint at port 7100 to serve queries. For example -
$ curl -s -G "http://localhost:7100/search" --data-urlencode "text=\"longest river in africa\"" | jq
[
{
"title": "Wikipedia: Nile (disambiguation)\n",
"abstractText": "The Nile, in northeast Africa, is one of the world's longest rivers.\n"
},
{
"title": "Wikipedia: Geography of the African Union\n",
"abstractText": "The African Union covers almost the entirety of continental Africa and several off-shore islands. Consequently, it is wildly diverse, including the world's largest hot desert (the Sahara), huge jungles and savannas, and the world's longest river (the Nile).\n"
},
{
"title": "Wikipedia: Tembakounda\n",
"abstractText": "Tembakounda in Guinea is the location of the source of the Niger River, West Africa's longest river, which eventually empties at the Niger Delta into the Gulf of Guinea distant. Tembakounda is in the Djallon Mountains, low mountains rising above the plateau area of the Guinea Highlands known as Fouta Djallon.\n"
}
]
The frontend has a cache optimization, where is caches the most frequent queries.
Performance Link to heading
The following numbers are from running the application on a Macbook M4.
| Operation | Duration |
|---|---|
| Reading and parsing the corpus 860MB file size | 46s |
| Index creation from scratch | 35s |
| Saving the index to RocksDB store | 27s |
| Loading the index from RocksDB | 24s |
Average response times for strings is on the order of a few milliseconds for an uncached query. Loading the index from disk saves us the expensive index construction process (46s + 35s) 💥
Next Steps Link to heading
- Optimize Memory Usage: Investigate methods to avoid loading the entire index into memory at startup.
- Support Boolean Queries: Implement logic for handling boolean search operations.
- Scalability Enhancements: Introduce sharding or distributed indexing to handle larger datasets efficiently.
- User-Friendly Enhancements: Improve the search API, add ranking mechanisms, and introduce more advanced query features.
The foundation is solid—there’s much more that can be built on top of it! Hope this was a fun read 🙂